
К сожалению, некоторые организации в IT обманывают клиентов, заявляя об использовании ИИ в своих технологиях, но при этом они даже не знают о пределах возможностей своих продуктов.
В новостной ленте часто можно наткнуться на организации, которые используют ИИ и машинное обучение для сбора и изучения тысяч данных пользователей для повышения удобства пользователей в универсальных мобильных приложениях. Или которые предсказывают поведение, используя «смесь машинного обучения и ИИ». Или любая другая красивая комбинация этих двух терминов.
Существует много путаницы с машинным обучением и искусственным интеллектом. Большинство людей вообще уверены, что это примерно одно и то же. Бывают ситуации, когда компании продают свои решения и сознательно игнорируют различия между терминами для более звучной рекламы.
Давайте же разберемся, в чем разница? Рассмотрим основные особенности искусственного интеллекта и машинного обучения.
Машинное обучение (ML)

Машинное обучение – это направление работы с ИИ, которое традиционно определяется как: "наука о компьютерных алгоритмах, которые автоматически улучшаются благодаря опыту". Машинка – это один из способов, с помощью которого человечество пытается создать «настоящий ИИ». Машинное обучение основывается на работе с большими наборами данных, путем изучения и сравнения данных для поиска общих паттернов и изучения нюансов.
Например, если предоставить программе машинного обучения много рентгеновских снимков с соответствующими симптомами, она сможет упростить или даже автоматизировать анализ рентгеновских изображений в будущем. Алгоритм будет сравнивать все эти разные изображения и находить общие шаблоны на изображениях, которые были помечены аналогичными симптомами. Кроме того, если добавить еще изображений, алгоритм будет сравнивать содержимое с установленными шаблонами, и сможет определять вероятность наличия симптомов, которые он выучил.
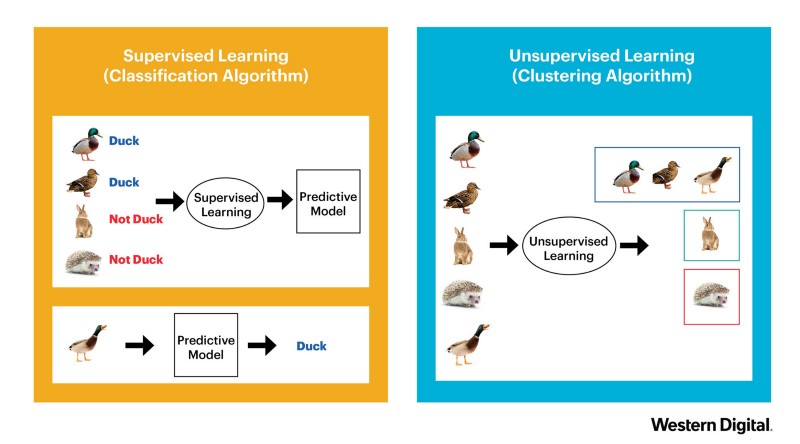
Метод машинного обучения из предыдущего примера называется «обучение с учителем» («supervised learning»). Алгоритмы обучения пытаются смоделировать отношения и зависимости между целевым прогнозируемым выходом и входными данными. Далее мы сможем прогнозировать выходные значения для новых данных на основе предыдущих, на которых алгоритм обучался.
«Обучение без учителя» («unsupervised learning»), еще один метод машинного обучения – это семейство алгоритмов машинного обучения, которые в основном используются для поиска шаблонов и описательного моделирования («descriptive modeling»). Эти алгоритмы не имеют выходных категорий или меток данных (модель обучается с немаркированными данными).
«Обучение с подкреплением» («reinforcement learning»), третий популярный способ машинного обучения, направлен на использование наблюдений, собранных в результате взаимодействия с окружающей средой, для принятия мер, которые максимизируют выигрыш. В этом случае алгоритм обучения подкрепления (называемый агентом) непрерывно учится из своей среды на протяжении многих итераций. В конце каждой итерации в модели обновляются значения весов – вероятность лучших исходов на каждом шаге.
Машинное обучение – это интересная штука, особенно если углубляться в сложные подвиды, например, глубокое обучение или разные виды нейронных сетей. Работа таких алгоритмов кажется волшебной и чем-то напоминает работу головного мозга.
Искусственный интеллект (AI)
Проблема термина в том, что его используют в совершенно разных областях и имеют в виду разные вещи. По словам Эндрю Мура, декана Школы компьютерных наук Университета Карнеги-Меллона, «Искусственный интеллект – это наука о способах создания компьютеров, которые ведут себя так, как по недавним представлениям мог бы вести себя только человеческий разум».
С одной стороны это короткое определение ИИ в одно предложение, с другой стороны даже оно показывает, о насколько широкой и неопределенной области мы говорим. Например, несколько десятилетий назад калькулятор считался ИИ, потому что математический расчет был чем-то, доступным только человеку. Сегодня калькуляторы есть абсолютно везде, и никто не считает их за ИИ, поэтому «по недавним представлениям» из определения изменяется со временем.
Получается, что определение ИИ сильно зависит от прогресса в технологиях. Машинное обучение лишь один из примеров. В прошлом для создания ИИ использовались совершенно другие методы. Например, Deep Blue, ИИ который победил чемпиона мира по шахматам в 1997 году, использовал алгоритмы поиска по дереву для оценки миллионов ходов на каждом шагу.
Сегодня ИИ символизируется интерактивными интерфейсами Google Home, Siri и Alexa; системами прогнозирования для видео у Netflix, Amazon и YouTube; алгоритмами хедж-фондов, используемых для совершения микротранзакций. Эти технологические достижения постепенно становятся важными в нашей повседневной жизни. Фактически, они являются умными помощниками, которые делают нас более продуктивными.
В отличие от машинного обучения, ИИ – это цель, которая постоянно изменяется, потому что тесно связана с технологическими достижениями. Поэтому есть очень размытые грани определения чего-то как ИИ, в то время как машинное обучение – это четко определенная технология. Возможно, лет через 20 сегодняшние инновации в областии ИИ будут считаться такими же простыми, как для нас сегодня калькуляторы.
Почему современные компании постоянно используют эти термины как будто они значат одно и то же?

Термин «искусственный интеллект» был введен в 1956 году группой исследователей, включая Аллена Ньюэлла и Герберта Саймона. После этого индустрия ИИ пережила множество колебаний. В первые десятилетия вокруг индустрии было много шумихи, и многие ученые согласились с тем, что искусственный интеллект человеческого уровня не за горами. Однако этого так и не произошло, поэтому для области наступили грустные времена: финансирование и интерес к ИИ значительно сократились.
Впоследствии организации пытались абстрагироваться от термина ИИ, который стал синонимом чего-то нереального и гиперболизированного, заменяя названия для своих изобретений на другие термины. Например, IBM описала Deep Blue как суперкомпьютер и прямо заявила, что не использует искусственный интеллект, хотя на самом деле это и был ИИ по рамках тех времен.
Чуть позже другие термины, такие как большие данные, предиктивная аналитика и машинное обучение, начали набирать популярность. В 2012 году машинное обучение, глубокое обучение и нейронные сети достигли больших успехов и стали использоваться во все большем числе областей. Организации внезапно начали использовать термины машинного обучения и глубокого обучения для рекламы своих продуктов.
Глубокое обучение начало выполнять задачи, которые невозможно было сделать с классическим программированием, основанным на строгих правилах. Области, такие как распознавание речи и лица, классификация изображений и обработка естественного языка, которые были на этапе зарождения, внезапно совершили огромные скачки в развитии. А зарплаты специалистов по машинному и глубокому обучению лишь подчеркивают, насколько эти технологии актуальны на сегодняшний день.
Все вышеперечисленное привело к возрождению шумихи вокруг искусственного интеллекта. Поэтому многие организации считают более выгодным использовать абстрактный термин «ИИ», который источает мистическую ауру, а не рассказывать более конкретно о том, какие технологии они используют. Это помогает им лучше продавать свои продукты.
При этом «инновационный искусственный интеллект», который эти организации якобы используют, оказывается методом машинного обучения или другой известной технологии.
Такой обман помогает компаниям создавать шумиху вокруг своих предложений и привлекать больше клиентов. Далее из-за несоответствия ожиданиям, эти организации вынуждены нанимать людей, чтобы восполнить недостатки своего так называемого ИИ. В конце концов эти действия, направленные на краткосрочную прибыль, могут вновь подорвать доверие к искусственному интеллекту, что вызовет повторение прошлого: люди будут сомнительно относиться ко всему, где упоминается этот термин, а компании будут пытаться избегать его использования.