
На связи Russian Hackers, и мы решили подготовить материал, который поможет как участникам, так и компаниям-партнерам хакатонов собрать комплексное представление о том какие задачи можно встретить на хакатонах и собственно чем они могут быть полезны компаниям. Но прежде небольшое пояснение про DS, AI, ML:
Data Science включает в себя задачи по искусственному интеллекту (AI), которые в свою очередь решаются с помощью машинного обучения - ML, а также другими методами, например, статистикой

Содержание статьи:
- Общие вводные
- Что необходимо предоставить для решения задач
- Какая польза от задачи на хакатон
- Примеры задач
- Ожидания от команд и проектов на хакатоне
- Какие следующие шаги чтобы это было продуктом
Общие вводные
Задачи связанные с DS бывают следующих типов:
- вот датасет (набор данных), придумайте сервис - продуктовые задачи
- вот датасет, вот задача, побейте скор (достигнутая ранее точность предсказания) - Kaggle (общепринятое обозначение подобных соревнований)
- вот “ничего”, соберите дата-сет - data-mining
- вот продукт, придумайте с чем интегрироваться (поиск API): задача не в самих алгоритмах, а в задачах использовать существующие AI решения, например, Yandex Speech2Text, Clarifai
В большинстве случаев решение будет сводится к следующим вариантам:
- классификация: ответ алгоритма – 0 или 1, прикладной пример: есть дефект на производственной ленте или нет
- регрессия: ответ алгоритма – вероятность от 0 до 1, прикладной пример: с какой вероятностью есть дефект на производстве)
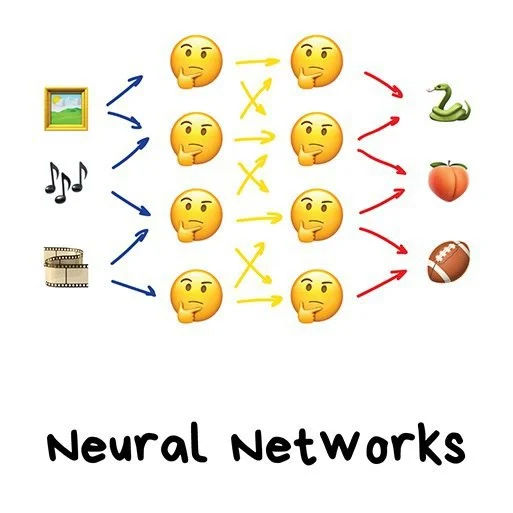
- CV: задачи по компьютерному зрению, прикладной пример – есть данные с камер, нужно определить: что за сущность на камере (классификация), какое действие совершено, и т.п.
- NLP: задачи по обработке языка, информации в текстовом виде, прикладной пример: есть отзывы банков, надо определить они написаны с негативом или позитивом

- explainable AI: задачи по интерпретации результатов. По-умолчанию модель - это черная коробка, которая выдает результат, но не выдает причины, которые стоят за ним. Алгоритмов, которые умеют обосновать работы, достаточно мало, но это одно из самых трендовых направлений. Прикладные примеры: подобные алгоритмы крайне важны в банкинге: скоринге кандидатов на кредит, на производствах, где необходимо узнать причину брака.
Также есть и другие менее популярные виды задач, и никто не отменял возможность комбинировать несколько задач в одной.
Что необходимо предоставить для решения задач
Железо
Для ряда задач нужно “железо” - серьезные вычислительные мощности:
- для всего похожего на изображения (видео и т.п.) нужны GPU (графические ускорители) – они ускоряют обучение моделей в 30-60 раз;
- для некоторых алгоритмов NLP и классических алгоритмов ML чаще нужно много CPU (процессорные мощности)

Датасеты
Это очень больная тема, так как данные чаще всего находятся под NDA. Что желательно подготовить для участников:
- чистые данные, на основе которых нужно предсказывать (Х) и
- цель обучения – что предсказываем (Y)
Здесь действует правило: чем больше данных, тем лучше. В случае с хакатоном должно быть ограничение на то, чтобы датасеты помещались в оперативную память компьютера объемом до 8 Gb (если предоставляются достаточные облачные мощности, то это ограничение может быть снято).
Оптимально, если это табличка с данными, следующего вида:
x_1 x_2 x_3 x_4 x_5 … x_n; y_1, … y_k …,
где с помощью x_i предсказывается y_k.
Данные могут быть анонимные или нет. Анонимность - мы не знаем что означает x_1 или x_2.
Анонимизация данных полезна:
- против NDA,
- против использования алгоритмов у конкурентов,
- когда хотим получить инсайд из машинного обучения, а не из интерпретации конкретного человека. Если данные не анонимные, люди выдумывают продуктовые фичи, а не инженерные и это часто хуже по качеству
Анонимизация данных плоха:
- в продуктовых кейсах
Важно обратить внимание на следующее:
- чтобы не было прямой зависимости X от Y, либо Y в прямом виде есть в X. Это называется leak в данных – это очень-очень-очень плохо;
- чтобы в Y не было перекосов по классам, например, данных, что все хорошо - много, что есть ошибка – единицы. Особенно это актуально, если речь идет о дефектах производства;
- чтобы в X были разные значения: если задача «отличить кошку от собаки», а в обучающей выборке только кошки сфинксы и Голден Ретриверы, то алгоритм на Хаски будет работать плохо;
- строк в датасете лучше иметь 10^5 - 10^7 – это оптимально. По объему – если это таблица с числами, то до 50Мб. Если картинки, видео и т.п. – отдельный архив;
- не всегда большее количество данных приводят к лучшему результату. Часто алгоритмы дают больший разброс, если они знают слишком много о данных, поэтому на хакатонах часто дают подзадачу “узнать, какие факторы самые важные”.
На практике сырые данные приводят к более плотным факторам. Например, были данные с сенсора пожарной безопасности и с датчика огня. На основе них сделали фактор “Начался пожар” = (огонь усилился И датчик сработал).
Какая польза от DS задачи на хакатон
Для дата-сентистов
- получить новые факторы для продакшна,
- убрать те факторы, которые не вносят вклад в модель,
- получить корреляцию ответов и данных,
- узнать какие внешние данные можно использовать для их работы,
- поиск актуальных статей, работающих в их сфере - опытные команды на практике имплементируют “state of the art” подходы из статей и протестируют их на ваших данных,
- трансфер похожих алгоритмов из других областей: например, алгоритмы МЛ диагностики ЭКГ сделали прорыв в нефтянке.
Для менеджмента
- генерация продуктовых фичей и их реализация,
- поиск команд для коллаборации/найма,
- технологический скаутинг — какие технологии можно использовать для решения задач,
- 20-40 прототипов за хакатон,
- поиск обоснования (explainable ai): почему произошла та или иная вещь,поиск утечек в данных.
Примеры задач
Первый пример
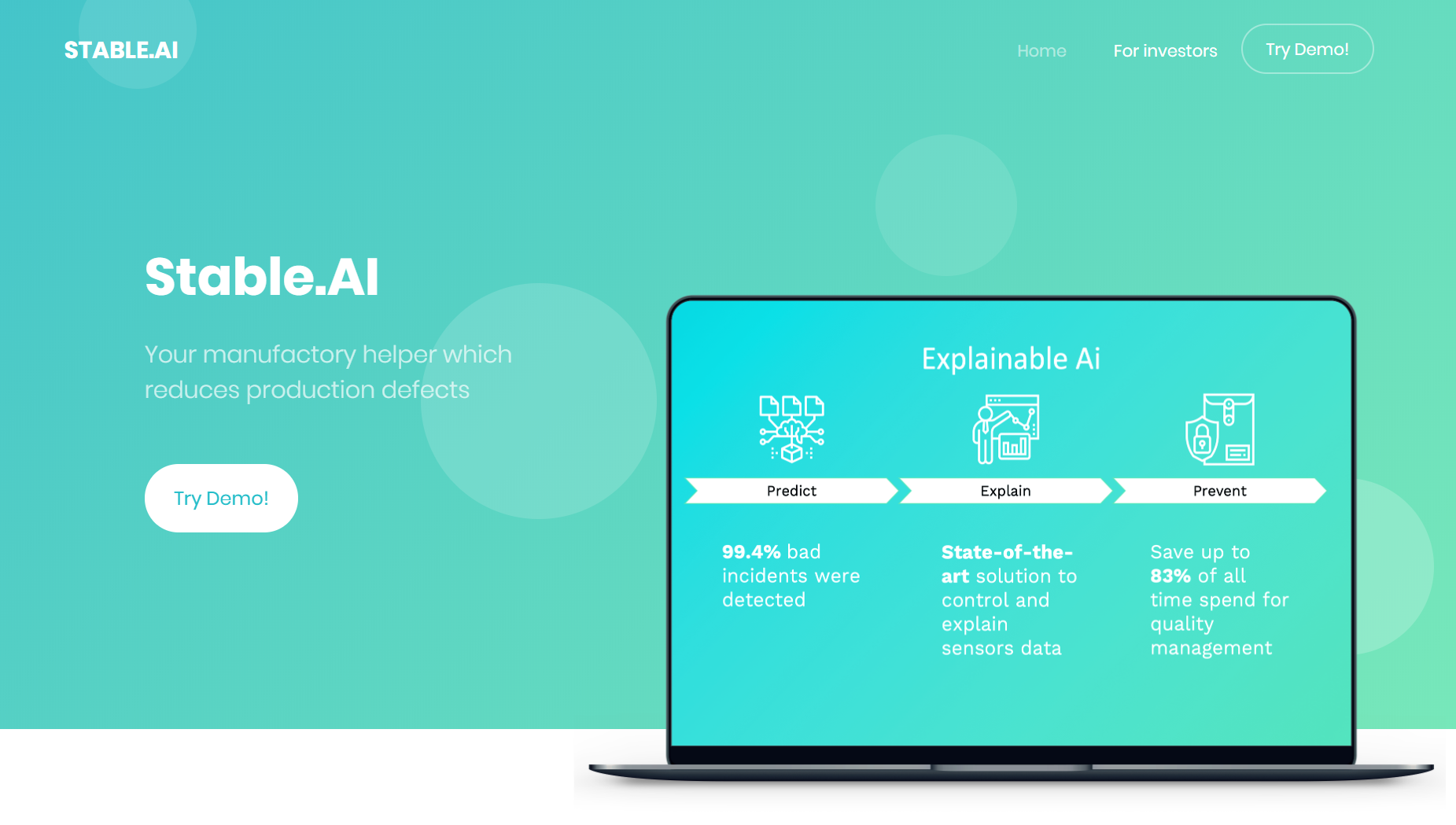
Bosch дали датасет с производства – сварки деталей. Датасет состоял из тысяч сенсоров, снимающих данные на ленте с течением времени. Задача – объяснить какие события влияют на дефекты производства (Explainable AI).
Кто курирует:
- Data Scientist,
- Инженер производства, ответственный за данные,
- Менеджер, уточняющий вопросы по производству,
- Ивентщик, волонтеры, собирающие обратную связь от команд по данным.
Результат:
Сервис – помощник для производства, уменьшающий количество дефектов на производстве. https://stable-ai.github.io
Как работает
1) Predict. Классификация 99.4% дефектов на производстве
2) Explain. Ансамбль из разных алгоритмов предсказывает дефекты. Каждый из алгоритмов выдает наиболее приоритетные фичи для производства и их вклад, а также общий разброс всех алгоритмов. Ансамбль алгоритмов уверен в предсказании в 83% случаев, а значит эти дефекты можно автоматизировать и экономить до 83% времени на Quality Assurance
3) Prevent. Знание по ошибкам позволяют устранять их. По исследованию McKinsey http://bit.ly/mckinsey_stableai до 30% затрат производства полупроводников тратят на поиск брака.
Второй пример
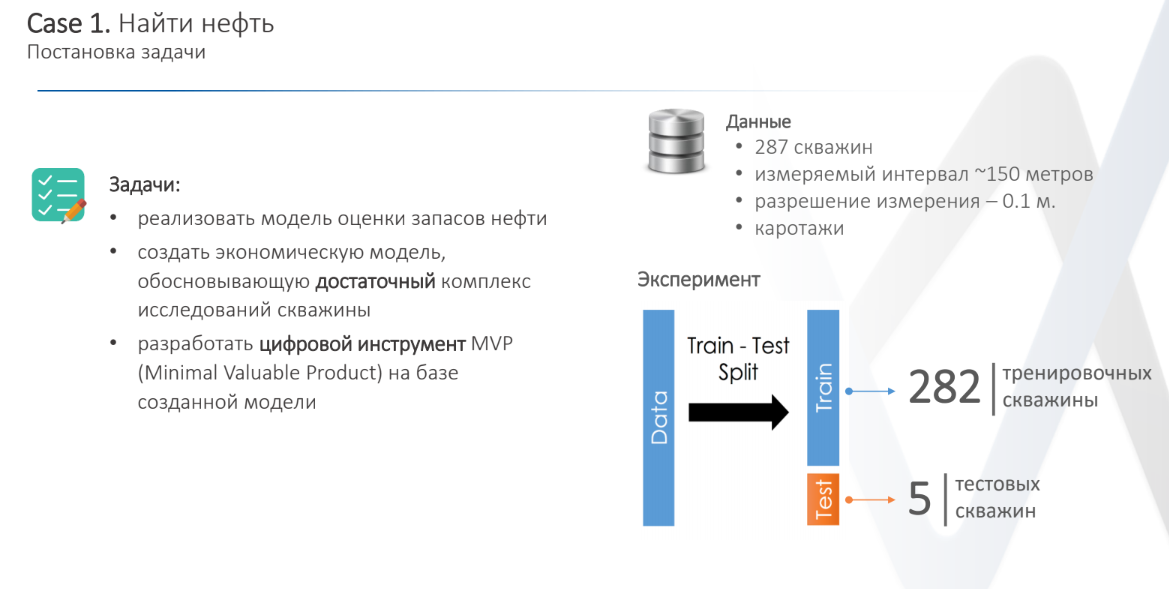
CET MIPT, BCG, Газпромнефть дали задачи Найти нефть и Добыть нефть. Опишу первую задачу: найти нефть.
Дали данные со скважин. Данные были на основе результатов исследований (каротажей). Каждое исследование стоит денег. Нужно максимизировать предсказание алгоритма по поиску нефти и минимизировать суммарную стоимость исследований. Бонусом была задача предсказания пород почвы
Вот хороший пример как оформлялись данные и задача: https://drive.google.com/drive/u/0/folders/1P9TzqcxfQW5cnmTealPwD8DNQFKoE8z3
Ожидания от команд на хакатоне
Что участники будут делать
- изучать существующие решения,
- пилить модели,
- делать новые алгоритмы,
- разворачивать на инстансе машину: использовать облачные вычисления для ускорения работы над проектом.
Что участники не будут делать
- слишком много работать на вашем стеке технологий,
- чистить данные,
- снимать дорогие сервера,
- придумывать данные за вас,
- MVP, так как результат хакатона - это Proof of Concept,
- деплой в облаке, продакшн реди.
Портрет участников

Уровень участников будет очень сильно зависеть от организации процесса привлечения команд и их последующего отбора. Здесь важно понимать, что даже если задача внешне выглядит сложной и интересной, на нее могут прийти как участники,
- для которых все заканчивается использованием самых простых готовых алгоритмов,
- так и специалисты, например, из передовых исследовательских отделов по DS IT компаний, которым интересно попробовать новые алгоритмы, или профессиональные участники Kaggle соревнований, чей интерес - получить еще одну “медаль”.
Как участники выигрывают:
- нашли лик в данных и “заабузили” его,
- ИЛИ сделали ансамбль из алгоритмов градиентного бустинга,
- засунули туда фичей побольше,
- еще больше фичей,
- нашли внешние датасеты и еще улучшили качество.
Какие следующие шаги чтобы это было продуктом
Что необходимо делать, чтобы решения доживали до продакшена:
- нужно упаковывать решение с хакатона в условный докер,
- давать доступ к данным под NDA и сохранять результаты работы,
- обсуждать интеграцию с текущей архитектурой компании;
Потребуется как работа со стороны команды, так и со стороны компании. Одним из простых вариантов решения будет пригласить команду доделать это как аутсорс разработчикам или нанять их в штат.
Также на практике часто бывают случаи, что компании нуждаются в решении других задач, нежели они представили на хакатоне. Это может быть связано как с невозможностью предоставления открытого доступа ко всем данными и процессам, которые необходимы для решения задачи, в рамках хакатона, так и в неполной проработке проблемы на стороне компании до мероприятия. В данном случае хакатон является инструментом поиска и валидации способных команд и отдельных участников, которые смогут после полноценного погружения качественно решить задачу.