Что можно называть MVP, когда речь идет о машинном обучении? Перевод статьи Дата Трэна, главы Data Science отдела в Idealo Internet.
Пару месяцев назад я покинул Pivotal и присоединился к idealo.de (ведущему веб-сайту для сравнения цен в Европе и одному из крупнейших порталов на немецком рынке электронной коммерции), чтобы помочь им интегрировать машинное обучение в свои продукты. Помимо обычных задач, таких как создание команды по data science, настройка инфраструктуры и всяких административных вещей, мне пришлось определить план разработки продуктов на основе ML. Также мне нужно было определить минимальный жизнеспособноый продукт (MVP) для продуктов машинного обучения. Вопрос, с которым я часто сталкиваюсь, здесь, в idealo, а также в свое время в Pivotal, – что на самом деле означает хороший MVP? В этой статье я расскажу о различных аспектах хорошего MVP для продуктов машинного обучения, опираясь на опыт, который я приобрел до сих пор.
Что такое MVP?
В Pivotal Labs я познакомился с мышлением в духе lean startup, которое популяризируется Эриком Рисом. Lean startup – это современная методология разработки продуктов. Основная идея заключается в том, что, создавая продукты или услуги итеративно, постоянно собирая отзывы клиентов, вы можете снизить риск того, что продукт/услуга потерпит неудачу (сделать-измерить-изучить).
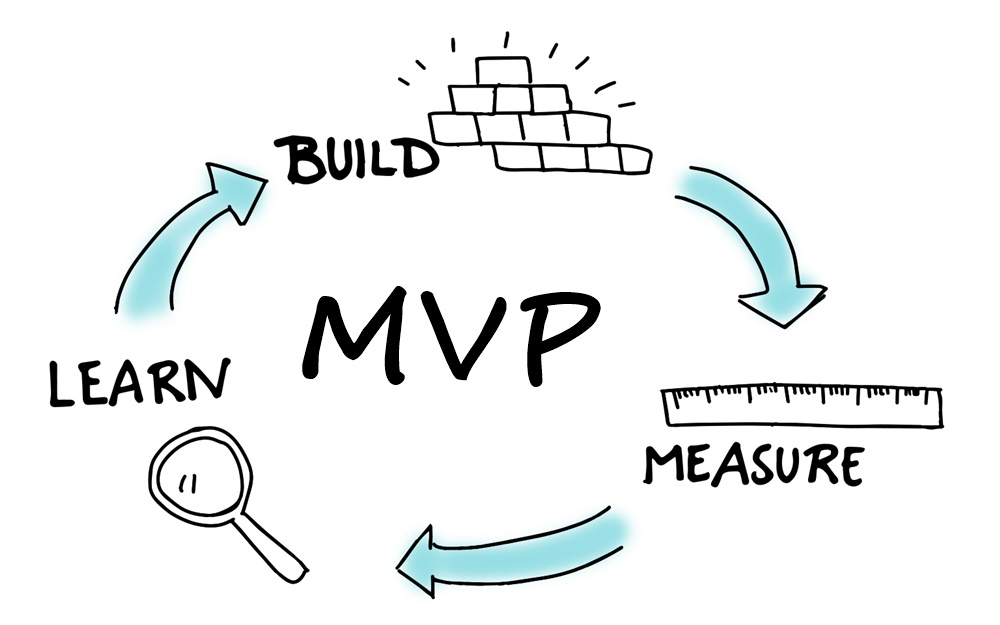
Неотъемлемой частью концепции сделать-измерить-изучить является MVP, который, по сути, является «версией нового продукта, которая позволяет команде собрать максимальное количество достоверных знаний о клиентах с наименьшими усилиями».
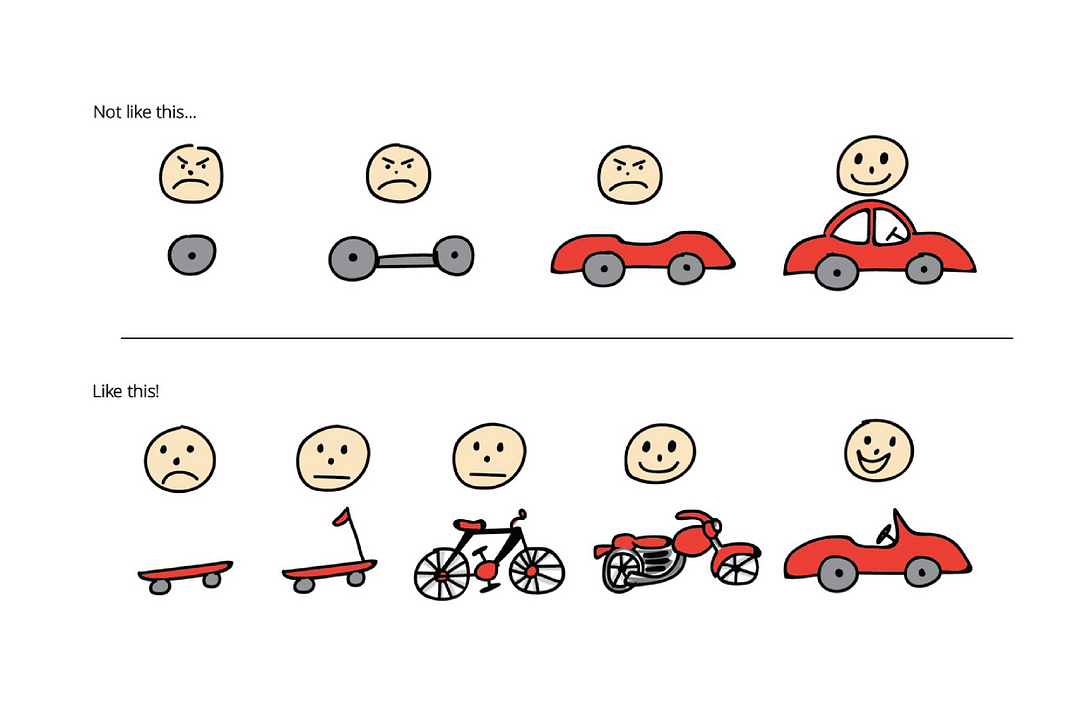
По сути, мы начинаем с минимальных усилий, чтобы проверить идею. В этом случае мы просто берем два колеса и доску. Затем мы отправляем это на рынок и получаем обратную связь, чтобы постоянно улучшать наш продукт, добавляя к нему больше фич. В таком случае мы получили автомобиль, который построен на обратной связи с потребителем.
Хорошо известным примером является Airbnb. В 2007 году Брайан Чески и Джо Геббиа хотели начать собственный бизнес, но также не могли позволить себе арендную плату в Сан-Франциско. В то же время в город приезжала дизайнерская конференция. Они решили сдать свое жилье участникам конференции, которые не нашли гостиницу поблизости. Они сфотографировали свою квартиру, разместили ее на простом веб-сайте, и вскоре у них было три гостя на время конференции.
Этот небольшой тест дал им ценную информацию о том, что люди будут готовы платить за проживание в чужом доме, а не в отеле, и что клиентами могут быть не только молодые выпускники колледжей. После этого они запустили Airbnb, а остальное — уже история.
В противоположность этому, другой подход состоит в том, чтобы создавать автомобиль сразу, без промежуточных итераций. Однако такой подход может оказаться безумно затратным. В конце концов мы можем создать товар, который не нужен клиенту. Возьмем Juicero в качестве примера. Они привлекли $ 120 млн от инвесторов, чтобы создать хорошо спроектированную соковыжималку, которую они выпустили после некоторого времени разработки по очень высокой цене (первоначально $ 699, затем снижена до $ 399). Наряду с машиной вы также можете купить пакеты с соком, наполненные сырыми фруктами и овощами, по цене 5-7 долларов. В итоге компания закрылась, потому что не понимала, что потребителям просто не нужна дорогостоящая машина соковыжималка. Они действительно не понимали своих клиентов. А от разорения их могло спасти простое ислледование пользователей.

Как концепция MVP относится к продуктам машинного обучения?
Концепция MVP также может быть применена к машинному обучению, потому что в конце концов машинное обучение также является частью общего продукта или конечным продуктом. Учитывая это, есть три важных определения:
1. Minimum Viable Model
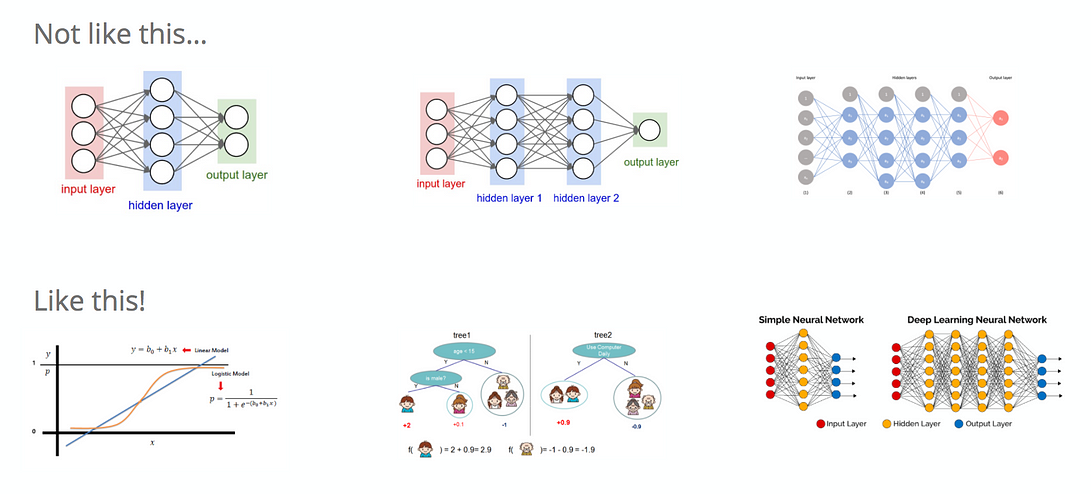
Одной из важных частей продукта ML является само моделирование. Давайте предположим, что у нас есть задача классификации, когда мы хотим классифицировать некоторые данные по заранее определенным категориям, таким как хот-дог и не хот-дог!

Возможным подходом к решению этой задачи классификации было бы использование нейронной сети с одним скрытым слоем. Затем мы будем тренировать и оценивать модель. В зависимости от результатов, мы можем продолжать улучшать нашу модель. Дальше мы добавили бы еще один скрытый слой и затем повторили бы то же упражнение. Затем, в зависимости от результатов, мы можем добавить все больше и больше скрытых слоев. Этот подход довольно прост и на самом деле является лучшим решением для проблемы хот-дог/не хот-дог, потому что не требуется никакой разработки функций (по сути, мы можем взять исходное изображение в качестве входных данных).
Однако, для большинства задач классификации, (если они не являются специфичными задачами, с которыми можно столкнуться в компьютерном зрении или понимании естественного языка), это не лучший способ решить проблему. Основным недостатком глубокого обучения, как правило, является его низкая интерпретируемость. Обычно трудно интерпретировать результаты работы нейронной сети. Более того, вы потратите огромное количество времени на настройку параметров нейронной сети, а прирост производительности модели будет незначителен.
Начните с простого и определите базовую модель
Более разумный подход для большинства задач классификации заключается в том, чтобы начать с линейной модели, такой как логистическая регрессия. Хотя во многих реальных приложениях предположение о линейности не выполняется, логистическая регрессия справляется довольно хорошо и служит хорошим эталоном, то есть базовой моделью. Его основными преимуществами также является интерпретируемость, и вы получаете условные вероятности довольно легко, что очень удобно во многих случаях.
Затем, чтобы улучшить модель, а также ослабить предположение о линейности, вы можете использовать древовидные модели. В этом случае есть два варианта: бэггинг или бустинг. Оба используют деревья решений, но с разными способами обучения. Наконец, когда все варианты исчерпаны и вы хотите продолжать улучшать свою модель, можно использовать методы глубокого обучения.
2. Minimum Viable Platform

Во время работы в Pivotal Labs я работал над множеством проектов, чтобы помочь компаниям из списка Fortune 500 начать работу с данными. Многие из этих проектов начинались с огромных инвестиций в инфраструктуру компаний. Они тратили много денег на покупку больших платформ данных, так называемых «озер данных». Затем, купив их, они начали загружать данные в свои озера данных, даже не задумываясь о возможных вариантах использования. Затем они услышали о загадочном Apache Spark и также добавили это в слой. Теперь, когда ИИ стал сверхпопулярен, они также начали покупать графические процессоры и добавлять ко всему фреймоврки глубокого обучения, например TensorFlow. Звучит здорово – иметь все крутые инструменты в одном месте? Самая большая проблема, однако, заключалась в том, что после помещения всех данных в их озеро данных, данные не подходили для их задач. Они либо не собрали нужные данные, либо их просто не существует в природе.
Сначала попробуйте облако
Более разумным подходом было бы не думать об аппаратном/программном обеспечении, а скорее сперва сосредоточиться на работе. При таком подходе компании могут на раннем этапе понять, какие данные необходимы для решения проблемы, а также могут избежать ошибки в данных. Помимо этого, есть много проблем машинного обучения, которые могут быть полностью решены на локальной машине. Компаниям не всегда нужно вкладывать огромные средства в свою инфраструктуру. И в случае, если данные действительно большие, они могут использовать облачных провайдеров, таких как AWS или Google Cloud, где можно легко раскрутить кластер c Apache Spark. Если речь идет о задачах с глубоким обучением, также существуют несколько вариантов решений. Компании могут использовать уже упомянутых облачных провайдеров или сервисы, такие как FloydHub, который предлагает им платформу как услугу (PaaS) для обучения и развертывания моделей глубокого обучения в облаке.
3. Minimum Viable (Data) Product
По сути, существует множество примеров продуктов с данными, таких как чат-боты, детекторы спама и многие другие, – этот список очень длинный. Но в этом случае я сосредоточусь на рекомендательных сервисах, так как сейчас я работаю в сфере электронной коммерции.
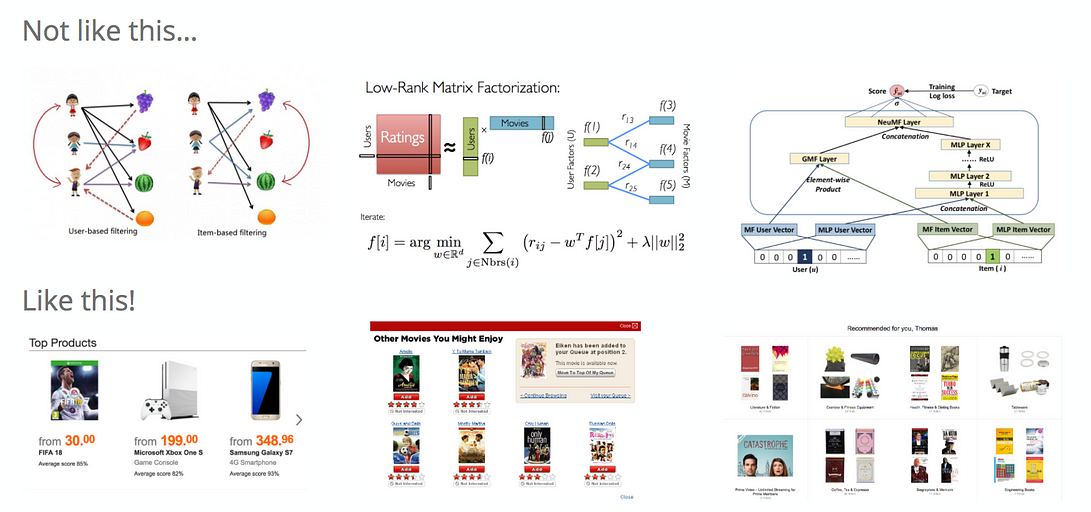
Один из способов начать с настройки рекомендательного сервиса – это использовать простые алгоритмы подобия, а затем перейти к методам матричной факторизации. Наконец, мы могли бы также попробовать более сложные модели, включающие методы глубокого обучения (например, глубоко структурированная семантическая модель). Однако такой подход не очень рекомендуется. Рекомендации могут принимать разные формы. Например, рекомендации, данные вашими друзьями или "100 самых популярных продуктов". Не каждый сложный алгоритм, который мы используем, обязательно приведет к успеху, но его необходимо протестировать. На самом деле, не бойтесь начинать создавать сервис рекомендаций без машинного обучения.
Сделайте правильный выбор...

Таким образом, правильным подходом было бы сначала установить фреймворк A/B-тестирования и метрики для оценки (например, показатель отказов или рейтинг кликов), а затем начать с простого прототипа, подобно топовым продуктам. После тестирования того, что пользователи действительно склонны нажимать на эти рекомендации (иногда им нужно сначала к этому привыкнуть, особенно если это новая функция продукта), и в конечном итоге они могут купить эти рекомендуемые товары, мы могли бы попробовать более сложные подходы, такие как методы совместной фильтрации. Например, мы могли бы создать рекомендацию на основе того, что пользователи, купившие определенный элемент, также заинтересованы в этих элементах, или пользователи, просмотревшие этот элемент, также заинтересованы в этих элементах. Разнообразие вариантов бесконечно для «пользователей, которые ... этот элемент также заинтересован в этих элементах».
Итог
В этой статье я рассказал о том, что означает MVP для продуктов машинного обучения. По сути, речь идет о том, чтобы начинать с малого, а затем итерировать. Кроме того, чтобы дать более четкое представление о том, что я имею в виду под MVP для продуктов машинного обучения, я рассмотрел три основных аспекта, которые я считаю критическими для хорошего продукта, связанного с ML:
- a minimum viable model,
- a minimum viable platform,
- and a minimum viable (data) product.